 임효인 기자
임효인 기자 |
| 왼쪽부터 최정우 KAIST 전기및전자공학부 교수, 이동헌 박사, 권영후 석박통합과정, 김도환 석사과정. KAIST 제공 |
KAIST는 이동헌 박사·권영후 석박통합과정생·기도환 석사과정생으로 구성된 최정우 교수 연구팀이 '공간 의미 기반 음향 장면 분할' 분야에서 세계 1위 성과를 거뒀다고 11일 밝혔다.
연구팀이 참가한 분야는 여러 음원이 혼합된 다채널 신호의 공간 정보를 분석해 개별 소리를 분리하고 18종으로 분류하는 기술 난이도가 매우 높은 분야다.
이동헌 박사는 2025년 초 트랜스포머와 맘바 아키텍처를 결합한 세계 최고 성능의 음원 분리 인공지능(AI)을 개발한 데 이어 대회 기간 연구팀과 함께 1차로 분리된 음원의 파형과 종류를 단서로 다시 음원 분리와 분류를 수행하는 '단계적 추론 방식'의 AI 모델을 완성했다.
사람이 복잡한 소리를 들을 때 소리의 종류나 리듬, 방향 등 특정 단서로 개별 소리를 분리해 듣는 방식을 AI가 모방한 모델이다. 연구팀의 기술은 '음원의 신호대 왜곡비 향상도'가 가장 높아 기술적 우수성을 자랑했다.
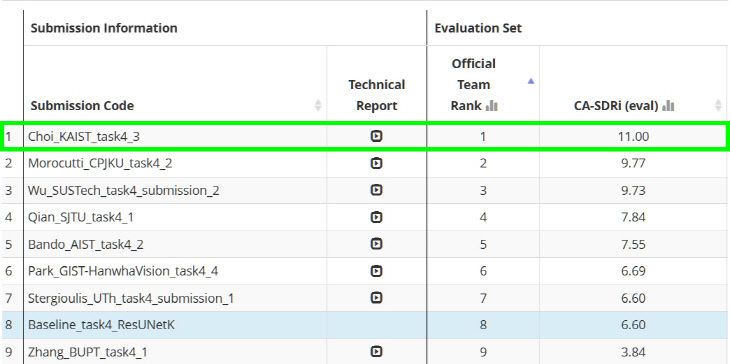 |
| 대회 결과 보드. 신호대 왜곡비 향상도(CA-SDRi)가 높을수록 높은 점수다. KAIST 제공 |
최정우 교수는 "연구팀은 최근 3년간 세계 최고의 음향 분리 AI 모델을 선보여 왔다. 그 결과를 공식적으로 인정받는 계기가 돼 기쁘다"며 "난이도가 대폭 향상되고 타 학회 일정과 기말고사로 불과 몇 주간만 개발이 가능했음에도 집중력 있는 연구를 통해 1위를 차지한 연구팀 개개인이 자랑스럽다"고 말했다. 임효인 기자
중도일보(www.joongdo.co.kr), 무단전재 및 수집, 재배포 금지





![[2025 국감] 청년몰 사업 폐업률 절반가량... 소진공 국감서 뭇매](https://dn.joongdo.co.kr/mnt/webdata/content/2025y/10m/23d/78_2025102301001548300067501.jpg)
![[유통소식] 대전 백화점과 아울렛서 가을과 겨울 만끽해볼까](https://dn.joongdo.co.kr/mnt/webdata/content/2025y/10m/23d/78_2025102301001550100067611.jpg)












